- PM Tech House 🏠
- Posts
- A Comprehensive Guide to Automating Your Job Search with AI Agents
A Comprehensive Guide to Automating Your Job Search with AI Agents
Maximizing Efficiency and Effectiveness in Your Job Search Journey
TL;DR: Job searching is a time-consuming process, often taking months and hundreds of applications to find the right role. AI-powered job search engines can revolutionize this by automating tasks like screening job postings, evaluating companies, and matching roles to resumes. Using tools like internet search and data retrieval, AI agents can filter, rate, and summarize job opportunities in seconds, saving job seekers countless hours. This article walks through building such a system, leveraging frameworks like CrewAI and LLMs like GPT-4, to create a scalable, personalized solution. Future improvements could include resume optimization, interview preparation, and real-time job monitoring, offering job seekers unparalleled flexibility and efficiency.
JOB POSTINGS IN LAST 24 HRS [US]
Product Manager | DoorDash → Reach out to Nate Lemieux ([email protected])
Growth Product Manager | Kikoff → Reach out to Autumn Bujtor ([email protected])
Product Manager | Sentient Foundation → Reach out to Bawar Hamad ([email protected])
Apply ASAP!
Job searching is often a challenging and lengthy process, sometimes stretching over weeks or even months. The time it takes to secure a role depends on various factors like expertise, market demand, and industry trends. According to the U.S. Bureau of Labor Statistics, as of March 2024, the median duration of unemployment (including passive job seekers) was 21.6 weeks—roughly 5 months.
On a human lifespan scale, this represents a significant chunk of time lost to sifting through countless job postings and applications. Research shows that job seekers typically need to submit between 100 to 200+ applications to land the right position, though this number can vary based on economic conditions, market dynamics, and individual skill levels.
The sheer volume of effort and time invested in job hunting highlights the need for efficient, scalable solutions. By streamlining the process, we can save individuals thousands of hours, making the journey to employment faster and less exhausting.
Challenges Facing Every Job Seeker
Navigating a job market overflowing with listings to find the perfect role that aligns with your skills and needs is no easy task. If you’ve been in this position, you know how draining it can be to sift through hundreds of postings, comparing skills, salary ranges, and requirements. The longer the search drags on, the more motivation dwindles, increasing the risk of settling for a less-than-ideal role.
The time it takes to land the right job depends on factors like experience, timing, and how sought-after your skills are. External elements, such as industry trends and organizational changes, also play a role, often beyond your control.
In this article, we address these pain points by focusing on how an AI-powered job search engine can optimize the process. By streamlining job matching, we aim to tackle critical challenges like:
Key Challenges
Job Advertisements Search: The process typically starts with selecting the right platform to find job postings. Job seekers then filter listings based on specific criteria and evaluate each one by analyzing its content. To maximize opportunities, many use multiple platforms, but managing and tracking listings across different sources quickly becomes overwhelming.
Job Advertisements Evaluation: Once a job posting is found, it needs to be assessed for fit. Key questions arise: Does it align with my skills and experience? Do I meet the required years of experience? Is the location suitable? What languages are needed? Does the salary match my expectations? When does the role start? Answering these questions for each listing is time-consuming and mentally taxing.
Organization Evaluation: Researching potential employers is another critical step. Common factors include employee reviews, market performance, and company reputation. For cross-market opportunities, this process becomes even more complex, as additional criteria specific to each market must be considered.
Job Shortlisting: After reviewing dozens—or even hundreds—of listings, job seekers narrow down their options to a shortlist. This requires a rating system based on personal preferences and priorities, such as role suitability, company culture, or career growth potential. The task involves extensive comparison and decision-making, which can be exhausting.
These challenges involve repetitive tasks, strong analytical reasoning, and digesting large amounts of information to create a clear, actionable plan.
This is where LLM-powered agents can make a significant impact. By automating and streamlining these processes, they can save job seekers countless hours, reduce stress, and improve the overall efficiency of the job search.
AI Agent's Crucial Role In Optimizing The Job Search Process
Imagine having hundreds of assistants who can scan job postings, evaluate companies, and recommend roles tailored to your needs—all in a fraction of the time it would take you to do it manually. This is the power of AI agents in optimizing the job search process. By automating and personalizing every step, they drastically cut down the hours spent sifting through listings and researching employers.
Let’s break down what AI agents bring to the table:
1. Agents can use tools
AI agents can leverage specialized tools to enhance their functionality. For example, they can access the internet, use APIs to gather data, and interact with a wide range of resources beyond their training data. This allows users to customize how agents tackle specific tasks, making them highly adaptable to individual needs.
2. Agents can digest a substantial amount of information
With the increasing size of context windows (1ml+) for AI models, and even reaching infinite context windows, the amount of information agents can digest and reason about is ever-growing. Distributed correctly, agents can analyze an infinite amount of information and provide users with a final summarized version.
3. Agents can reason
While there can be limitations to the reasoning capabilities of AI Agents, the new, improved, and optimized models being published more & more often are closing in on that gap. Considering the task at hand of analyzing job advertisements and comparing those to a user query based on some parameters, the task is potentially considered a straightforward analysis task for a highly trained AI agent.
4. Agents can summarize and structure results
Processing information is only half the battle—delivering it in a clear, structured way is equally important. Well-engineered prompts and validation steps help agents avoid errors (like hallucinations) and provide reliable, easy-to-digest summaries.
5. Agents can collaborate
Different agents can tackle different aspects of a problem, bringing varied perspectives and expertise. By collaborating, they optimize the final results, ensuring a comprehensive and well-rounded solution.
6. Agents are scalable
AI agents can handle tasks in parallel, making them ideal for large-scale problems. For instance, multiple agents can divide a batch of job postings, each focusing on a specific step (e.g., filtering, evaluating, or summarizing). The results are then combined into a final, cohesive output. This distributed approach ensures speed and scalability, even across multiple job platforms.
How can we put together all those capabilities for our use case?
Putting It All Together
By combining these capabilities, we can build an AI-powered job search engine that:
Automates Screening: Quickly filters job postings based on user criteria.
Evaluates Roles and Companies: Analyzes job descriptions and employer profiles to ensure a good fit.
Delivers Personalized Recommendations: Provides tailored job suggestions in a structured, easy-to-understand format.
Scales Effortlessly: Handles large volumes of data across multiple platforms without compromising speed or accuracy.
This approach not only saves time but also ensures job seekers find roles that truly align with their skills, preferences, and career goals. In the next sections, we’ll explore how to design and implement such a system.
Integrating AI Agents into the Job Search Process
To create a solution that fully leverages AI capabilities, we introduce agents at every stage of the job search process. Here’s how they enhance each step:
Agents use specialized tools to fetch job advertisements based on the user’s query. This ensures the initial pool of listings is relevant and aligned with the job seeker’s preferences.
Agents analyze each job posting, comparing it to the user’s resume and query. They provide a rating along with a clear explanation of why the role is a good (or poor) fit, ensuring transparency and relevance.
Using internet access tools, agents gather detailed information about the companies behind the job postings. They evaluate factors like company reputation, employee reviews, and market performance, assigning a rating score to each organization.
Finally, agents compile the findings into a structured, easy-to-understand format. By following a predefined model, they deliver concise summaries that highlight the best opportunities tailored to the user’s needs.
The next section will dive into utilizing the listed AI Agents' capabilities for building a job search engine.
Hands-on Tutorial: Building an AI-Powered Job Search Engine
In the current section, we will walk through the complete implementation step by step and end with analyzing the final results and potential improvements.
Project Structure
In this section, we’ll walk through the step-by-step implementation of an AI-powered job search engine. By the end, we’ll analyze the results and explore potential improvements.
A
configsdirectory that contains all needed configs and parameters to configure agents (role, background, backstory) and tasks (description and expected output)A
datadirectory containing all needed data to test the job search engineA
modelsdirectory containing defined models for the expected output schemaA
utilsdirectory containing needed support functionsagents_factory.pyandtasks_factory.pyare used to dynamically generate instances of agents and tasks based on configurations defined.
project/
├── configs
│ └── agents.yml # Agents configuration
│ └── tasks.yml # Tasks configurations
│
├── data
│ ├── sample_jobs.json # JSON file containing job listings
│ └── sample_resume.txt # Text file containing a resume
│
├── models
│ └── models.py # ORM models
│
├── utils
│ └── utils.py # Utility functions and helpers
│
├── .env # containing all needed environment variables
│
├── agents_factory.py # Factory class for creating agent instances
├── tasks_factory.py # Factory class for creating task instances
│
└── main.py # MainFramework
The project will utilize the crewAI framework to build the end-to-end application. It provides a straightforward interface to build AI Agents with assigned tasks and specific tools. It integrates very well with other available AI frameworks, thus fitting perfectly to the scope of this article.
Ensure first that a Python environment (in my case using python-3.11.9) is available and install the framework with all the tools needed.
pip install 'crewai[tools]' Installation of crewai[tools] package should cover all the needed packages to run the application.
Tools
AI agents need specific tools to perform their tasks efficiently. Which tools they use depends on the workflow design and how data is shared between agents. For our use case, we’ll use two key tools, both available in CrewAI.
FileReadTool
On a production scale, where a large list of reliable APIs providing job data can be managed, the preferred agent tools are those capable of interfacing with multiple providers and fetching job information based on selected parameters.
For the scope of our application, we will work with a pre-retrieved JSON response, sample_jobs.json, containing a list of job details to keep the focus on demonstrating the solution.
A generated resume, sample_resume.txt, is also available to test the ratings provided by agents.
SerperDevTool
Agents will be tasked to gather information about organizations and provide rating feedback to users. This tool supports the process by enabling agents to search the internet. To use the tool Make sure that you create an account on serper.dev to acquire the API KEY needed and load it into the environment.
Ensure that the API key is defined in .env file.
SERPER_API_KEY=<>Tools can be directly imported
from crewai_tools import FileReadTool, SerperDevToolData
A sample_jobs.json contains a JSON response of a list of sample job advertisements synthetically AI-generated as testing data for our use case.
While the job data presented in the article is in JSON format, it could be easily in any other format for agents to parse, such as personally collected job description data documents stored as simple text, PDF, or Excel files.
Fully utilizing the search process requires agents to use tools to interface with job platforms APIs for full automation and scalability of the data ingestion process. Examples of such official job search API providers are Glassdoor or Jooble.
{
"jobs": [
{
"id": "VyxlLGIsICxELGUsdixlLGwsbyxwLGUscixELGUsbSxhLG4sdCxTLHkscixhLGMsdSxzLGUsLCwgLE4=",
"title": "Web Developer",
"company": "Apple",
"description": "As a Web Developer at CQ Partners, you will be a leader in the structuring, maintaining, and facilitating of websites and web-based applications...",
"image": "<https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQAkPEjEwMeJizfsnGN-qUAEw8pmPdk357KIzsi&s=0>",
"location": "Syracuse, NY",
"employmentType": "Full-time",
"datePosted": "17 hours ago",
"salaryRange": "",
"jobProvider": "LinkedIn",
"url": "<https://www.linkedin.com/jobs/view/web-developer-at-demant-3904417702?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic>"
},
{
"id": "VyxlLGIsICxELGUsdixlLGwsbyxwLGUsciwsLCAsVSxYLC8sVSxJLCwsICxCLHIsYSxuLGQsaSxuLGc=",
"title": "Web Developer, UX/UI, Branding, Graphics",
"company": "Adobe",
"description": "Degree required: Bachelor's degree in relevant field...",
"image": "<https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSV7-v1EkEhWtAh8W8WaqPD6vMQG2uBi0GOOOmb&s=0>",
"location": "Columbia, MD",
"employmentType": "Full-time",
"datePosted": "1 day ago",
"salaryRange": "",
"jobProvider": "LinkedIn",
"url": "<https://www.linkedin.com/jobs/view/web-developer-ux-ui-branding-graphics-at-adg-creative-3903771314?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic>"
},
......Additionally a sample_resume.txt file which contains a generated resume for an experienced data scientist.
Tasks
Tasks are distributed to agents equipped with the right tools and skills to complete them.
Each task is defined with a description, an expected output, and an agent responsible for completing it.
# configs/tasks.yml
job_search:
description: |
find a list jobs that fulfill the following requirements: {query}
expected_output: A structured output as a valid json with the list of jobs found with all their information. Make sure that field names are kept the same.
job_rating:
description: |
Using your tools to find the resume file information.
Provide an additional rating on the jobs you received in context according to the Resume information.
The rating is between 1-10 where 10 is the best fit. Every job should have a rating.
Additionally add a rating_description field that explains the reasoning behind the number of rating in 1 or 2 sentences.
Make sure that all information about the jobs is also maintained in the output.
expected_output: A structured output as a valid json of the list of jobs found and their respective ratings. Make sure that field names are kept the same.
evaluate_company:
description: |
Using your tools find information about the company of jobs.
Information can include company culture reviews, company financial reports, and stock performance.
provide an additional rating for the company in a field called company_rating.
The rating is between 1-10 where 10 is the best rating. Every job should have a rating.
Additionally add a company_rating_description field that explains the reasoning behind the number of rating in 1 or 2 sentences.
Make sure that all information about the jobs is also maintained in the output.
expected_output: A structured output as a valid json of the list of jobs found and their respective ratings, make sure to structure all information according this model {output_schema}
structure_results:
description: |
Use all the context to structure the output as needed for the final reporting.
expected_output: A structured output as a valid json of the list of jobs found and their respective ratings. Make sure that the final output you provide is a valid json with schema {output_schema} A TasksFactory class is used to generate all needed tasks.
# project/tasks_factory.py
from textwrap import dedent
from typing import Optional
from crewai import Agent, Task
from utils.utils import load_config # Load YAML
class TasksFactory:
def __init__(self, config_path):
self.config = load_config(config_path)
def create_task(
self,
task_type: str,
agent: Agent,
query: Optional[str] = None,
output_schema: Optional[str] = None,
):
task_config = self.config.get(task_type)
if not task_config:
raise ValueError(f"No configuration found for {task_type}")
description = task_config["description"]
if "{query}" in description and query is not None:
description = description.format(query=query)
expected_output = task_config["expected_output"]
if "{output_schema}" in expected_output and output_schema is not None:
expected_output = expected_output.format(output_schema=output_schema)
return Task(
description=dedent(description),
expected_output=dedent(expected_output),
agent=agent,
)Agents
Agents have a role, goal, and backstory defined to best complete selected tasks.
# configs/tasks.yml
job_search_expert:
role: The best job search Agent
goal: Impress all requestors with finding the best job postings and advertisements
backstory: The most seasoned job search analyst with lots of expertise in the job market.
job_rating_expert:
role: The best job rating Agent
goal: Impress all requestors by your ability to find the best fitting job to a resume information by providing an accurate rating
backstory: The most seasoned job rating expert with lots of expertise in job search matching and rating
company_rating_expert:
role: The best company evaluator agent
goal: find all important information about a company to evaluate job suitability
backstory: The most seasoned company information finder and evaluator expert with lots of expertise in company evaluation and deep research
summarization_expert:
role: The best output validator and summarizer
goal: Making sure that the final output required by the task is fitting the task
backstory: The most seasoned reporting expert that knows how to report on the output as needed and in the right structure Similar to the TasksFactory An AgentsFactory class is used to generate all needed AI Agents based on their configuration.
# project/agents_factory.py
from typing import Any, List, Optional
from crewai import Agent
from utils.utils import load_config # Load YAML
class AgentsFactory:
def __init__(self, config_path):
self.config = load_config(config_path)
def create_agent(
self,
agent_type: str,
llm: Any,
tools: Optional[List] = None,
verbose: bool = True,
allow_delegation: bool = False,
) -> Agent:
agent_config = self.config.get(agent_type)
if not agent_config:
raise ValueError(f"No configuration found for {agent_type}")
if tools is None:
tools = []
return Agent(
role=agent_config["role"],
goal=agent_config["goal"],
backstory=agent_config["backstory"],
verbose=verbose,
tools=tools,
llm=llm,
allow_delegation=allow_delegation,
)LLM
The range of options for choosing LLMs is rapidly expanding, with new models being released almost every week. In this setup, we’ll use Azure OpenAI models, specifically the gpt-4-32k version 0613. However, feel free to adapt and test the code with your preferred LLM.
To work with Azure OpenAI models an API KEY and ENDPOINT are needed. Azure provides great documentation to set up and deploy such models.
We add the required environment variables to the .env file
OPENAI_API_VERSION = <>
AZURE_OPENAI_KEY= <>
AZURE_OPENAI_ENDPOINT = <>Use the code below to import and use the selected model.
from langchain_openai import AzureChatOpenAI
import os
azure_llm = AzureChatOpenAI(
azure_endpoint=os.environ.get("AZURE_OPENAI_ENDPOINT"),
api_key=os.environ.get("AZURE_OPENAI_KEY"),
deployment_name="gpt4",
streaming=True,
temperature=0 # We set this to 0to ensure a more consitent and accurate output
)Output Model
To ensure a final consistent output by agents, we define our desired output models.
# models/models.py
from typing import List, Optional
from pydantic import BaseModel
class Job(BaseModel):
id: Optional[str]
location: Optional[str]
title: Optional[str]
company: Optional[str]
description: Optional[str]
jobProvider: Optional[str]
url: Optional[str]
rating: Optional[int]
rating_description: Optional[str]
company_rating: Optional[int]
company_rating_description: Optional[str]
class JobResults(BaseModel):
jobs: Optional[List[Job]]Putting Everything Together: The Crew
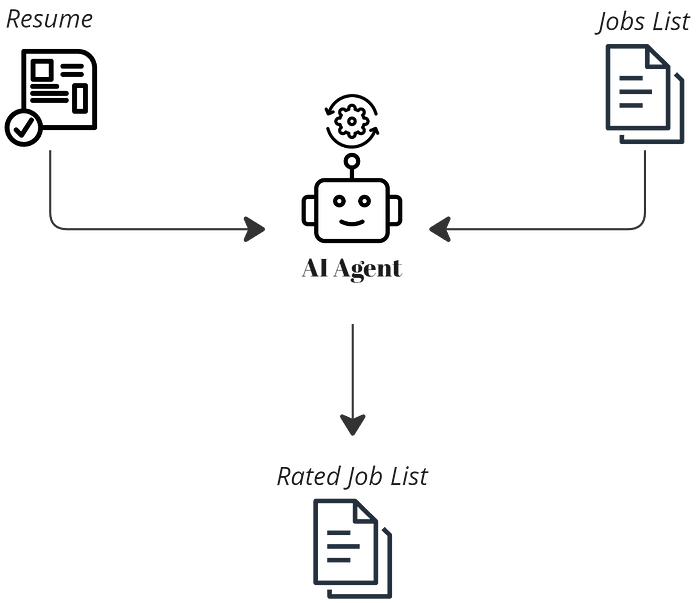
The diagrams earlier illustrate the sequence of tasks agents will follow to achieve the desired output. Each task’s completion is handed over to the next agent, optimized for a specific role. This sequential process aligns with our goals, but you can always restructure the design and adopt alternative strategies, such as agent collaboration or parallel processing, to tackle tasks differently.
Finally, we set up the search crew in main.py to create, assign, and run all AI agents, bringing the entire system to life.
import json
import os
from textwrap import dedent
from crewai import Crew, Process
from crewai_tools import FileReadTool, SerperDevTool
from dotenv import load_dotenv
from langchain_openai import AzureChatOpenAI
from pydantic import ValidationError
from agents_factory import AgentsFactory
from models.models import JobResults
from tasks_factory import TasksFactory
load_dotenv()
class JobSearchCrew:
def __init__(self, query: str):
self.query = query
def run(self):
# Define the LLM AI Agents will utilize
azure_llm = AzureChatOpenAI(
azure_endpoint=os.environ.get("AZURE_OPENAI_ENDPOINT"),
api_key=os.environ.get("AZURE_OPENAI_KEY"),
deployment_name="gpt4",
streaming=True,
temperature=0,
)
# Intialize all tools needed
resume_file_read_tool = FileReadTool(file_path="data/sample_resume.txt")
jobs_file_read_tool = FileReadTool(file_path="data/sample_jobs.json")
search_tool = SerperDevTool(n_results=5)
# Create the Agents
agent_factory = AgentsFactory("configs/agents.yml")
job_search_expert_agent = agent_factory.create_agent(
"job_search_expert", tools=[jobs_file_read_tool], llm=azure_llm
)
job_rating_expert_agent = agent_factory.create_agent(
"job_rating_expert", tools=[resume_file_read_tool], llm=azure_llm
)
company_rating_expert_agent = agent_factory.create_agent(
"company_rating_expert", tools=[search_tool], llm=azure_llm
)
summarization_expert_agent = agent_factory.create_agent(
"summarization_expert", tools=None, llm=azure_llm
)
# Response model schema
response_schema = json.dumps(JobResults.model_json_schema(), indent=2)
# Create the Tasks
tasks_factory = TasksFactory("configs/tasks.yml")
job_search_task = tasks_factory.create_task(
"job_search", job_search_expert_agent, query=self.query
)
job_rating_task = tasks_factory.create_task(
"job_rating", job_rating_expert_agent
)
evaluate_company_task = tasks_factory.create_task(
"evaluate_company",
company_rating_expert_agent,
output_schema=response_schema,
)
structure_results_task = tasks_factory.create_task(
"structure_results",
summarization_expert_agent,
output_schema=response_schema,
)
# Assemble the Crew
crew = Crew(
agents=[
job_search_expert_agent,
job_rating_expert_agent,
company_rating_expert_agent,
summarization_expert_agent,
],
tasks=[
job_search_task,
job_rating_task,
evaluate_company_task,
structure_results_task,
],
verbose=1,
process=Process.sequential,
)
result = crew.kickoff()
return result
if __name__ == "__main__":
print("## Welcome to Job Search Crew")
print("-------------------------------")
query = input(
dedent("""
Provide the list of characteristics for the job you are looking for:
""")
)
crew = JobSearchCrew(query)
result = crew.run()
print("Validating final result..")
try:
validated_result = JobResults.model_validate_json(result)
except ValidationError as e:
print(e.json())
print("Data output validation error, trying again...")
print("\n\n########################")
print("## RESULT ")
print("########################\n")
print(result)After task execution, we run a validation check to ensure that the JSON output is validated with the defined model schema. Additionally, we can potentially add further validation loops to ensure agents return the structure needed. We won't go into the details of implementing this complete process, nonetheless if interested feel free to check this great article on the topic.
Result Analysis
We simply run the code:
python main.pyFor our initial agent query, we input the following
Provide the list of characteristics for the job you are looking for:
A machine learning and data science job in the united states with a salary range of $100K- $170KThe query can be extended to further include locations, start date, industry etc.. and many other parameters one sees fit to filter and find job listings.
Output:
The terminal result shows that the first agent executed successfully and used the tools to retrieve the job list content.
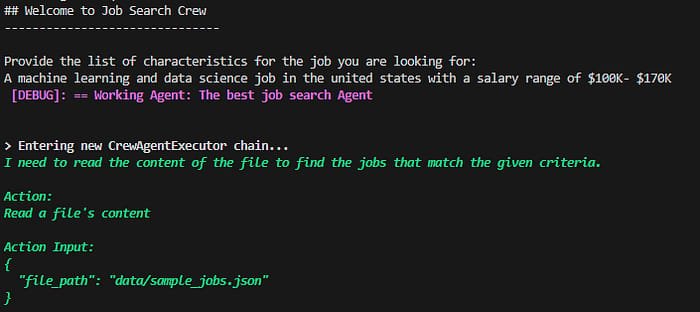
The agent then manages to filter the list and find the correct jobs based on the input query.
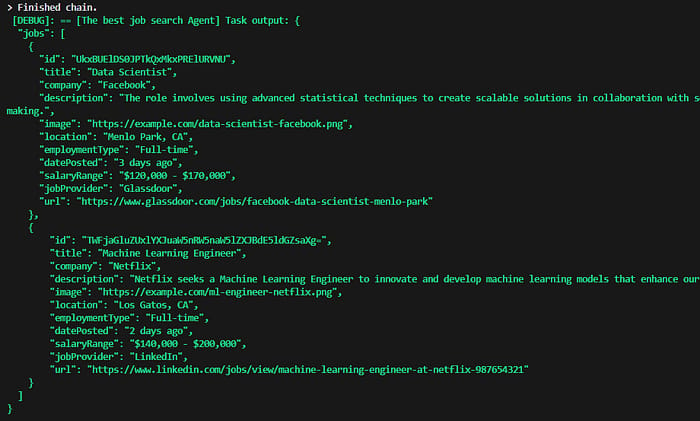
I will skip the detailed debugging information showing the Agent's progress and jump to the final result.
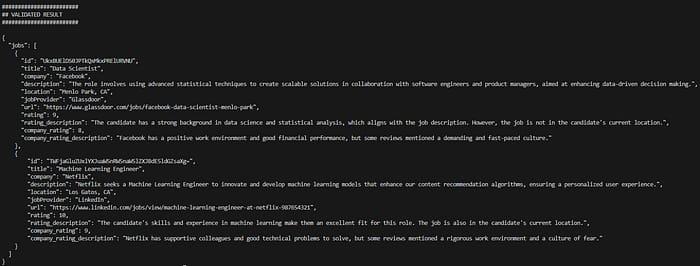
The result contains all the fields that were requested within the configured tasks, in addition to a valid final JSON result structure. We also observe the ratings provided and the reasoning behind those ratings as instructed.
Let's further test if those ratings are indeed are reflective of the matching process to the user's resume, we adjust the query as follows:
Provide the list of characteristics for the job you are looking for:
A web developer job in the united states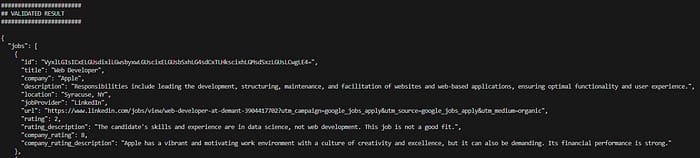
We observe that the ratings indeed were reduced with a request for a web developer role while having a resume optimized for machine learning and data science positions.
Conclusion
This article explored the transformative potential of AI agents in revolutionizing the traditionally time-consuming job search process, particularly in evaluating and matching job requirements with online advertisements. We outlined the key challenges job seekers face and demonstrated how AI agents can accomplish in seconds what might take humans weeks or even months. By walking through the implementation, we showed how to create and automate AI agents that leverage various tools to deliver personalized job recommendations.
In the coming months and years, AI will undoubtedly become a core component of job search engines and platforms, leading to faster and highly personalized job-matching experiences. However, having the ability to design and control your own AI-powered job search engine offers unparalleled flexibility and a significant advantage in navigating the job market.
Potential Improvements
The use case discussed and implemented in this article represents only a fraction of what’s possible with an AI-powered job search engine. As job search platforms increasingly integrate such tools, building your own cross-platform solution tailored to your needs can take this to the next level. The flexibility to choose models, customize agents, and adapt tasks to specific requirements offers a significant advantage.
Some additional features that would be interesting to dive into and build on top
Scale by incorporating a large amount of agents and tools interfacing with multiple job search platforms APIs.
Personalize tasks for adapting and improving resumes and cover letters based on job requirements with an automated application process.
Better Preparation by generating a list of potential interview questions based on job specifications and running mock interviews with agents
Improved Salary Negotiation by running extensive market research for the position and skills advertised.
Better Opportunities through continuous monitoring of advertisements with real-time handling and evaluation.