- PM Tech House 🏠
- Posts
- How DeepSeek-R1 is Outperforming OpenAI
How DeepSeek-R1 is Outperforming OpenAI
Discover how DeepSeek-R1’s open approach is accelerating AI innovation like never before.
James Wade
January 31, 2025
Imagine a future where the most advanced AI models are accessible to everyone, breaking free from corporate constraints. This vision is becoming a reality with DeepSeek, a pioneering AI company based in China, and its latest model, DeepSeek-R1. This innovative model not only democratizes access to cutting-edge AI technology but also empowers users to explore, enhance, and build upon its capabilities.
Over the past decade, AI has made leaps and bounds, thanks to breakthroughs like Google’s 2017 paper, "Attention Is All You Need," which introduced the Transformer architecture. This innovation paved the way for powerful large language models (LLMs) like OpenAI’s GPT series. However, OpenAI, which started as a non-profit aiming to democratize AI, has since shifted to a closed-source model, keeping its advancements under wraps.
Enter DeepSeek-R1, an open-source model that not only matches OpenAI’s latest o1 but surpasses it in key benchmarks. In this article, we’ll explore how DeepSeek-R1 was trained, the innovative techniques it uses, and why its open-source approach is a game-changer for the AI community.
Recently, OpenAI launched 'o1', a model that emphasizes extended reasoning through techniques like Chain-of-Thought and Reinforcement Learning. However, the specifics of this training process remain undisclosed. Enter DeepSeek, a Chinese company that has unveiled 'DeepSeek-R1', a model that not only matches but often surpasses OpenAI's o1 in various mathematical and coding benchmarks. This article explores how DeepSeek-R1 was developed and its implications for the future of AI.
How Are LLMs Usually Trained?
Before diving into DeepSeek-R1, let’s break down how most LLMs are trained. It’s a multi-step process that involves massive amounts of data, computational power, and clever algorithms.
Training LLMs typically begins with collecting vast amounts of text data from both public and proprietary sources. This data undergoes cleaning and formatting before being tokenized into text embeddings. The model is then pre-trained on this unlabeled data using self-supervised learning techniques on powerful GPUs or TPUs. This pre-training phase helps the model grasp language structures, including grammar and semantics.
This data comes from publicly available sources on the web or, at times, from proprietary sources.
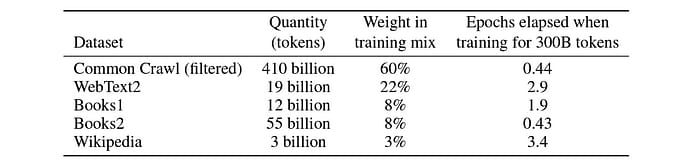
Data Collection: The first step is gathering a huge dataset, often from publicly available sources like books, websites, and articles. For example, GPT-3 was trained on a dataset containing hundreds of billions of words.
Pre-training: The model is then trained on this data using self-supervised learning. This phase teaches the model the basics of language—grammar, semantics, and how words relate to each other.
Supervised Fine-Tuning (SFT): After pre-training, the model is fine-tuned on specific tasks, like coding or math, using labeled datasets. This helps the model specialize in particular domains.
Alignment with Human Preferences: Finally, the model is aligned to ensure it generates helpful and harmless responses. Techniques like Reinforcement Learning from Human Feedback (RLHF) are commonly used here.
OpenAI’s o1 reportedly uses reinforcement learning to enhance its reasoning capabilities, but the exact details remain a mystery. DeepSeek-R1, on the other hand, takes a radically different approach by skipping SFT entirely and relying solely on reinforcement learning.
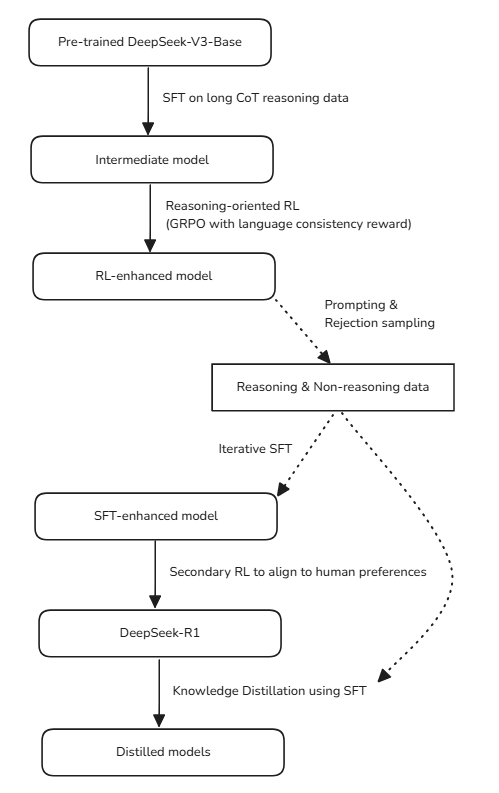
DeepSeek-R1’s Training: A New Approach
DeepSeek's approach diverges from traditional methods by eliminating supervised fine-tuning (SFT) in favor of direct reinforcement learning (RL). Starting with their base model, DeepSeek-V3-Base, they utilized a unique algorithm called Group Relative Policy Optimization (GRPO) instead of the commonly used Proximal Policy Optimization (PPO).
While PPO employs a critic/value model to compute advantages using Generalized Advantage Estimation (GAE), GRPO simplifies this by assessing advantages based solely on relative rewards among sampled outputs. This innovation reduces computational complexity and training costs.
PPO vs. GRPO: A Key Innovation
Most RL models use Proximal Policy Optimization (PPO), a popular algorithm developed by OpenAI. PPO involves two components: a policy model (which decides what action to take) and a critic model (which evaluates how good those actions are).
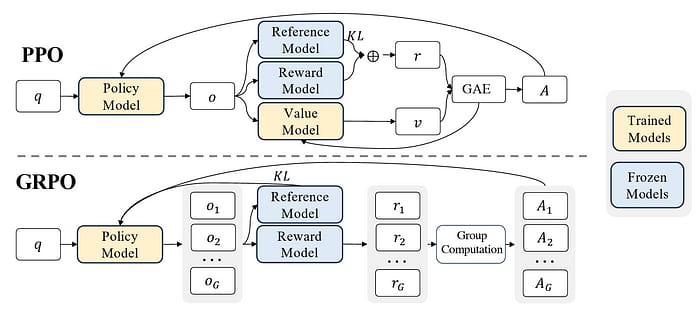
DeepSeek introduces Group Relative Policy Optimization (GRPO), a simpler and more efficient alternative. GRPO eliminates the critic model and instead calculates advantages based on the relative rewards of a group of outputs. This reduces computational complexity and training costs, making the process more scalable.
Reward System: Guiding the Model
In their RL training framework, DeepSeek employs a rule-based reward system to guide model optimization. Two primary types of rewards are utilized: accuracy rewards based on correct responses and format rewards ensuring adherence to specific response structures. The model is trained to articulate its reasoning process clearly before providing an answer.
The success of reinforcement learning hinges on the reward system employed during training. In DeepSeek's approach, researchers utilize a rule-based reward system rather than relying on a neural reward model. This choice mitigates issues like reward hacking and reduces the computational burden associated with retraining.
The RL process is guided by two types of rewards:
Accuracy Reward: This reward is based on whether the model’s response is correct. For example, if the model solves a math problem correctly, it gets a high accuracy reward.
Format Reward: This reward ensures the model follows a specific response format. For instance, the model is encouraged to enclose its reasoning steps in
<think>tags and the final answer in<answer>tags.
This dual-reward system ensures the model not only solves problems accurately but also presents its reasoning in a clear and structured way.
As training progresses, DeepSeek-R1-Zero emerges as a refined version of the base model, showcasing significant improvements in accuracy metrics across various benchmarks. For example, its pass@1 accuracy on AIME (2024) rises dramatically from 15.6% to 71%, demonstrating the effectiveness of this RL-focused training strategy.
DeepSeek-R1-Zero: The First Iteration
The initial RL-trained model, DeepSeek-R1-Zero, shows remarkable progress. Its accuracy on the AIME (2024) benchmark—a challenging math competition—jumps from 15.6% to 71%, rivaling OpenAI’s o1.
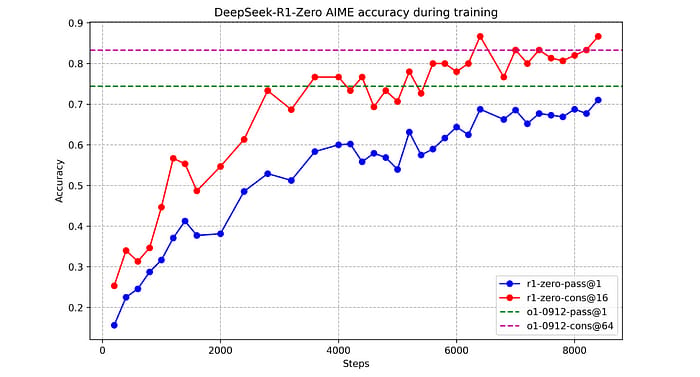
What’s fascinating is how the model naturally develops advanced reasoning behaviors. For example, it starts using techniques like self-reflection (revisiting and reevaluating its steps) and backtracking (exploring alternative approaches when stuck). These behaviors emerge organically as the model interacts with the RL environment, demonstrating its ability to tackle increasingly complex problems.
Eliminating SFT With Reinforcement Learning
In the traditional training of large language models (LLMs), supervised fine-tuning (SFT) plays a crucial role in enhancing model performance on specific tasks. However, DeepSeek has taken a bold step by eliminating SFT altogether in favor of direct reinforcement learning (RL). This innovative approach allows the model to evolve its reasoning capabilities without relying on labeled data, fostering a self-improving mechanism.
DeepSeek begins with its pre-trained base model, DeepSeek-V3-Base. Instead of the conventional SFT process, the team opts for RL to enhance reasoning performance. This method empowers the model to develop its reasoning skills autonomously, adapting and refining its responses based on feedback from the RL environment.
To facilitate this training, DeepSeek employs an in-house algorithm known as Group Relative Policy Optimization (GRPO), diverging from the widely used Proximal Policy Optimization (PPO) developed by OpenAI.
The key difference lies in how advantages are calculated. In PPO, a policy model collaborates with a critic/value model to compute advantages using Generalized Advantage Estimation (GAE). Conversely, GRPO eliminates the need for a critic/value model and instead computes advantages based on relative rewards among a group of sampled outputs. This shift not only simplifies the training process but also reduces computational costs significantly.
By removing SFT and leveraging GRPO, DeepSeek enables its model to explore various reasoning strategies organically. The result is a more flexible and adaptive learning process that enhances the model's ability to tackle complex problems effectively.
Further RL To Improve Reasoning In The SFT Model
After implementing supervised fine-tuning on DeepSeek-V3-Base using long CoT data, researchers proceeded with reinforcement learning training once again. However, this time they introduced a new language consistency reward aimed at mitigating language mixing issues observed previously.
This consistency reward incentivizes the use of target language words within reasoning processes. By rewarding models for maintaining language coherence throughout their responses, researchers aim to enhance both clarity and correctness in outputs.
The overall reward structure during this phase combines traditional accuracy and format rewards with this new language consistency aspect. This comprehensive approach ensures that while improving reasoning capabilities through RL training, models remain aligned with human preferences regarding language use and clarity.
This additional layer of refinement during RL training is termed Reasoning-oriented Reinforcement Learning, emphasizing both logical reasoning skills and effective communication through clear language usage. As researchers continue iterating through these processes, they gather valuable insights into optimizing LLM performance while addressing inherent challenges associated with complex problem-solving tasks.
They collect high-quality long Chain-of-Thought (CoT) data from various sources and refine it with human annotators to create a structured dataset for supervised fine-tuning. This dataset includes detailed reasoning processes followed by concise summaries.
After SFT, DeepSeek-R1 undergoes another round of RL training with an added language consistency reward aimed at reducing language mixing issues. This iterative approach enhances both reasoning quality and clarity in responses.
Cold-Start Data: The team collects long Chain-of-Thought (CoT) data from various sources, including outputs from other LLMs and DeepSeek-R1-Zero itself. This data is refined by human annotators to ensure clarity and coherence.
Reasoning-Oriented RL: After SFT, the model undergoes RL again, this time with an added language consistency reward to prevent language mixing. This dual approach balances reasoning power with readability, ensuring the model’s responses are both accurate and easy to understand.
SFT For Further Iterative Self-Improvement
The refined model generates more high-quality data, which is used for further SFT. This creates a feedback loop, where the model continuously improves itself.
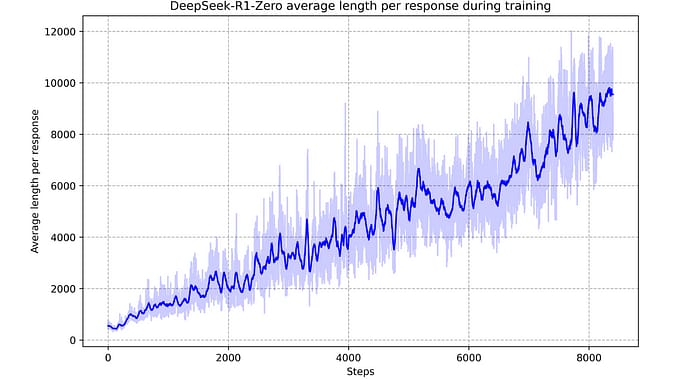
For example, the team collects 800,000 high-quality samples (600,000 for reasoning tasks and 200,000 for non-reasoning tasks like writing and translation) to fine-tune the model further.
This data is in the form of:
Reasoning data: 600k reasoning-related (in math, code, and logic) training samples are obtained with Rejection sampling by prompting the above model checkpoint to generate multiple reasoning trajectories (long CoTs) and rejecting the inappropriate ones using either predefined rules or a generative model (DeepSeek-V3)
Non-reasoning data: 200k training samples are obtained by prompting DeepSeek-V3 or from the SFT data used when training DeepSeek-V3. These are not related to reasoning but to tasks such as writing, factual question-answering, self-cognition and language translation.
These 800k samples in total are further used to supervised fine-tune the model.
Aligning with Human Preferences
To ensure the model is helpful and harmless, it undergoes a final RL phase. Rule-based rewards align reasoning responses, while a human-preferences-aligned reward model handles non-reasoning tasks.
To align its reasoning responses to human preferences, rule-based rewards are used, similar to what we previously discussed while training DeepSeek-R1-Zero.
For non-reasoning responses, a human-preferences-aligned reward model built on DeepSeek-V3 is used for its RLHF training.
This completes the training of DeepSeek-R1.
This step ensures the model generates responses that are not only accurate but also ethical and user-friendly.
Distilling DeepSeek-R1 into Smaller Models
DeepSeek-R1’s knowledge is distilled into smaller, more efficient models like DeepSeek-R1-Distill-Qwen-32B and DeepSeek-R1-Distill-Llama-70B. These models are designed to run on resource-constrained devices while maintaining high performance.
For example, DeepSeek-R1-Distill-Llama-70B outperforms OpenAI’s o1-mini and Anthropic’s Claude 3.5 Sonnet on multiple benchmarks, proving the effectiveness of knowledge distillation.
Performance Benchmarks: How Does DeepSeek-R1 Stack Up?
DeepSeek-R1 excels in several areas:
It outperforms previous models like DeepSeek-V3 on educational benchmarks such as MMLU and SimpleQA.
It also shows strong performance in long-context question answering and writing tasks.
When compared to OpenAI's o1 in mathematical reasoning and coding tasks, DeepSeek-R1 holds its ground or surpasses expectations.
DeepSeek-R1 shines in multiple benchmarks:
Mathematical Reasoning: Outperforms o1 on AIME and MATH-500.
Coding: Excels in LiveCodeBench and Codeforces.
Language Tasks: Matches or surpasses GPT-4 on MMLU and GPQA Diamond.
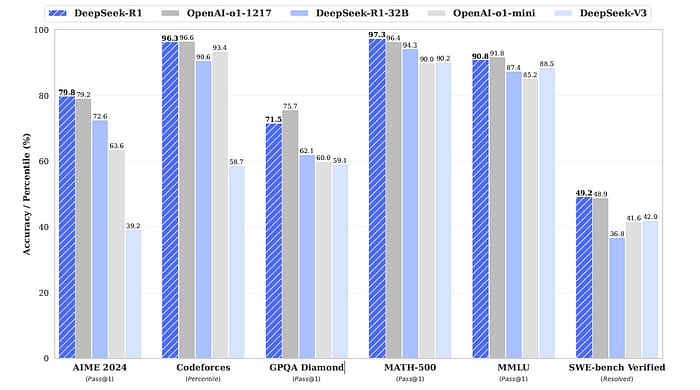
Even its distilled models, trained only with SFT, outperform larger models like QwQ-32B-Preview.
Limitations
Despite its strengths, DeepSeek-R1-Zero faces challenges such as mixing languages and inconsistent formatting in its responses. To address these issues, researchers experimented with SFT using carefully curated long Chain-of-Thought data before applying RL training again. This process involved gathering reasoning examples from various sources and refining them through human annotation.
After SFT, a new language consistency reward was implemented during RL training to further enhance clarity and coherence in responses. This iterative process culminates in a refined model that aligns more closely with human preferences while maintaining high performance across various benchmarks.
The Future of Open-Source AI
DeepSeek-R1’s open-source approach is a significant step toward democratizing AI. Projects like Hugging Face’s Open-R1 are already building on its research, showcasing the power of collaborative innovation.
DeepSeek also employs knowledge distillation to create smaller models that retain the capabilities of DeepSeek-R1 while being more resource-efficient. Using 800k training samples derived from previous models, they successfully distilled multiple Qwen and Llama models without additional RL training.
The distilled models have shown impressive results against competitors, particularly in educational benchmarks and coding tasks. For instance, DeepSeek-R1-Distill-Qwen-32B outperforms OpenAI's o1-mini significantly on the AIME benchmark.
Conclusion
DeepSeek-R1 is more than just a powerful LLM—it’s a testament to the potential of open-source AI. By making its training process transparent, DeepSeek is accelerating AI progress and inspiring a new wave of innovation. The future of AI is open, and DeepSeek-R1 is leading the charge. DeepSeek-R1 represents a significant leap forward in AI development through innovative training methodologies that prioritize efficiency and reasoning capabilities without sacrificing transparency. By leveraging direct reinforcement learning and knowledge distillation techniques, DeepSeek is set to accelerate AI progress while fostering an open-source ethos that encourages collaboration within the AI community. As we look ahead, the implications of these advancements could reshape our understanding of what AI can achieve.